Abstract
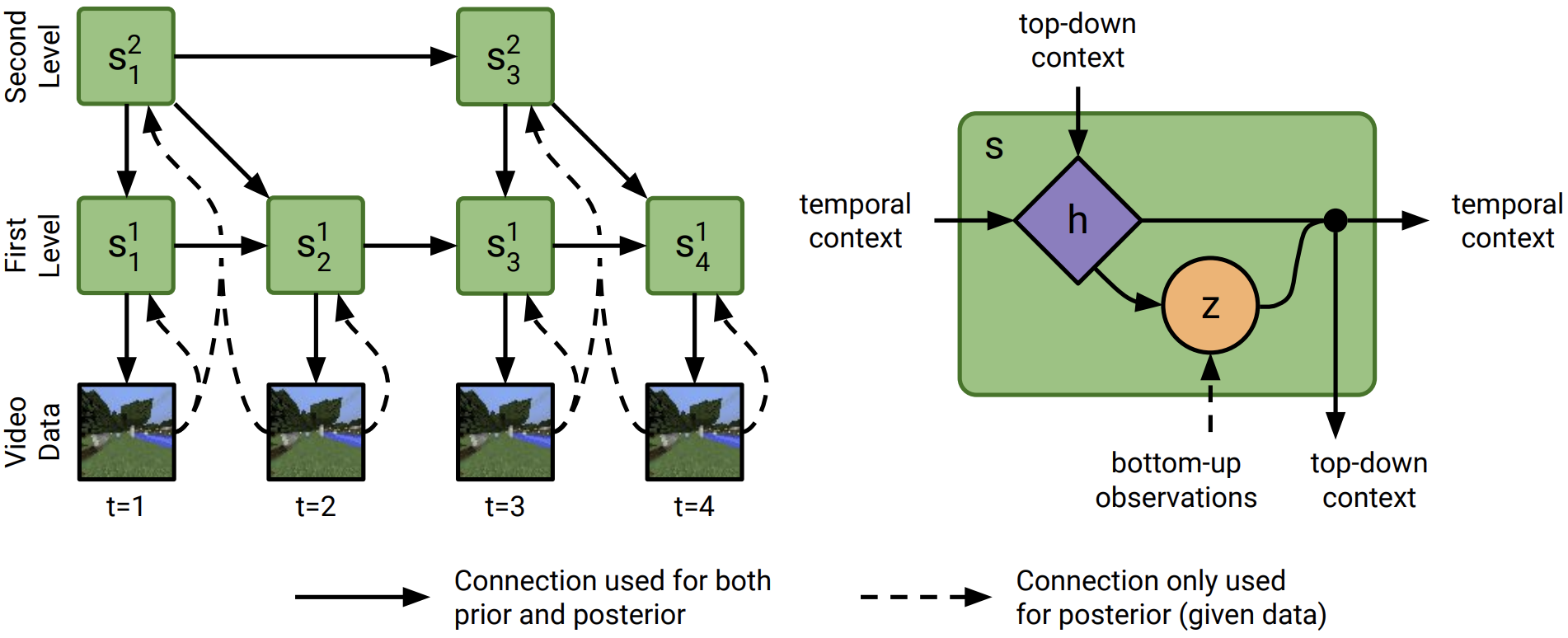
Deep learning has enabled algorithms to generate realistic images. However, accurately predicting long video sequences requires understanding long-term dependencies and remains an open challenge. While existing video prediction models succeed at generating sharp images, they tend to fail at accurately predicting far into the future. We introduce the Clockwork VAE (CW-VAE), a video prediction model that leverages a hierarchy of latent sequences, where higher levels tick at slower intervals. We demonstrate the benefits of both hierarchical latents and temporal abstraction on 4 diverse video prediction datasets with sequences of up to 1000 frames, where CW-VAE outperforms top video prediction models. Additionally, we propose a Minecraft benchmark for long-term video prediction. We conduct several experiments to gain insights into CW-VAE and confirm that slower levels learn to represent objects that change more slowly in the video, and faster levels learn to represent faster objects.
Architecture