
Abstract
Developing a general algorithm that learns to solve tasks across a wide range of applications has been a fundamental challenge in artificial intelligence. Although current reinforcement-learning algorithms can be readily applied to tasks similar to what they have been developed for, configuring them for new application domains requires substantial human expertise and experimentation. Here we present the third generation of Dreamer, a general algorithm that outperforms specialized methods across over 150 diverse tasks, with a single configuration. Dreamer learns a model of the environment and improves its behaviour by imagining future scenarios. Robustness techniques based on normalization, balancing and transformations enable stable learning across domains. Applied out of the box, Dreamer is, to our knowledge, the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula. This achievement has been posed as a substantial challenge in artificial intelligence that requires exploring farsighted strategies from pixels and sparse rewards in an open world. Our work allows solving challenging control problems without extensive experimentation, making reinforcement learning broadly applicable.
Benchmarks
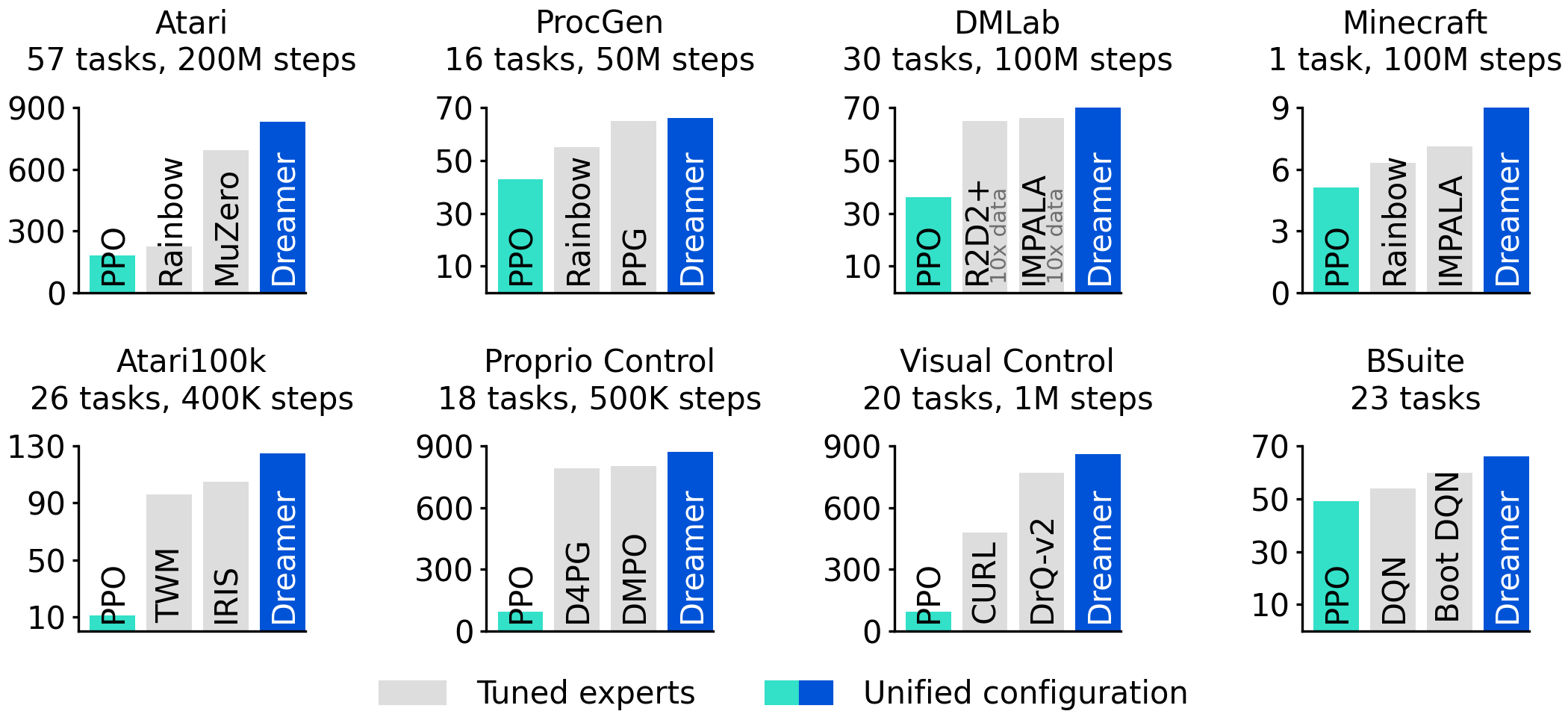
Using fixed hyperparameters across all domains, Dreamer outperforms tuned expert algorithms across a wide range of benchmarks and data budgets. Dreamer also substantially outperforms a high-quality implementation of the widely applicable PPO algorithm. Dreamer overcome the need for expert knowledge and extensive experimentation when solving new problems, making reinforcement learning broadly applicable.
Scaling
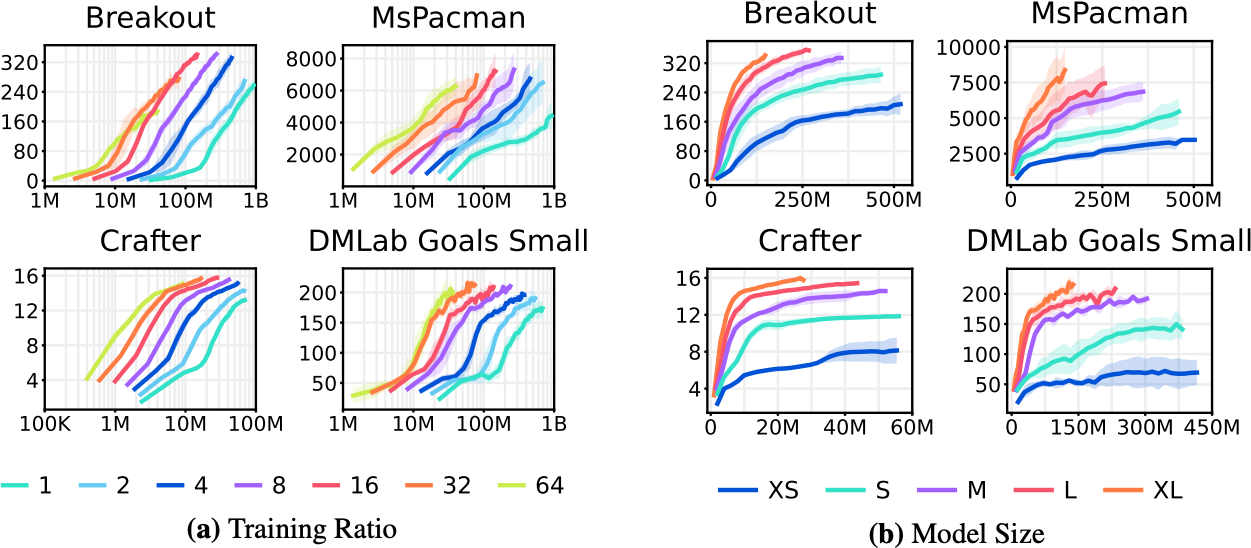
Due to its robustness, Dreamer shows favorable scaling properties. Notably, using larger models consistently increases not only its final performance but also its data-efficiency. Increasing the number of gradient steps further increases data efficiency. Dreamer thus offers a predictable way for practitioners to increase performance by increasing computational resources.
Minecraft
Collecting diamonds in the popular videogame Minecraft without human data has been widely recognized as a milestone for artificial intelligence, because of the sparse rewards, exploration difficulty, and long time horizons in this procedurally generated open-world environment. Dreamer is the first algorithm that collects diamonds in Minecraft from sparse rewards, without expert demonstrations or curricula, solving this challenge. The video shows the first diamond that it collects, which happens at 30M environment steps or 17 days of playtime.
Below, we show uncut videos of runs during which Dreamer collected diamonds. We find that it succeeds across many starting conditions, which requires searching the world for trees, swimming across lakes, and traversing mountains. Note that a reward is provided only for the first diamond per episode, so the agent is not incentiviced to pick up additional diamonds.
Start Videos